
My AI System Got Too Productive to Manage. So I Built a Dashboard in Three Hours.
When the governance layer generates more intelligence than you can track, you don’t need better habits. You need infrastructure.


Last week, I published a case study about building a live events app in two days using a governed AI practice. The system — decision logs, constraint files, session protocols — was the point. The app was the proof.
Here’s what I didn’t mention: by the time that case study went live, I was running seven concurrent workspaces. Each with its own operating document, decision log, and constraint file. Cross-workspace handoffs tracked in a shared file. Time logged in decimal hours. Every session reading the previous session’s state before starting.
If your AI practice doesn’t accumulate intelligence between sessions, it’s not a practice. It’s a series of one-offs that happen to use the same tool. Mine accumulates by design. And by late February it had accumulated enough that I could no longer see it all.
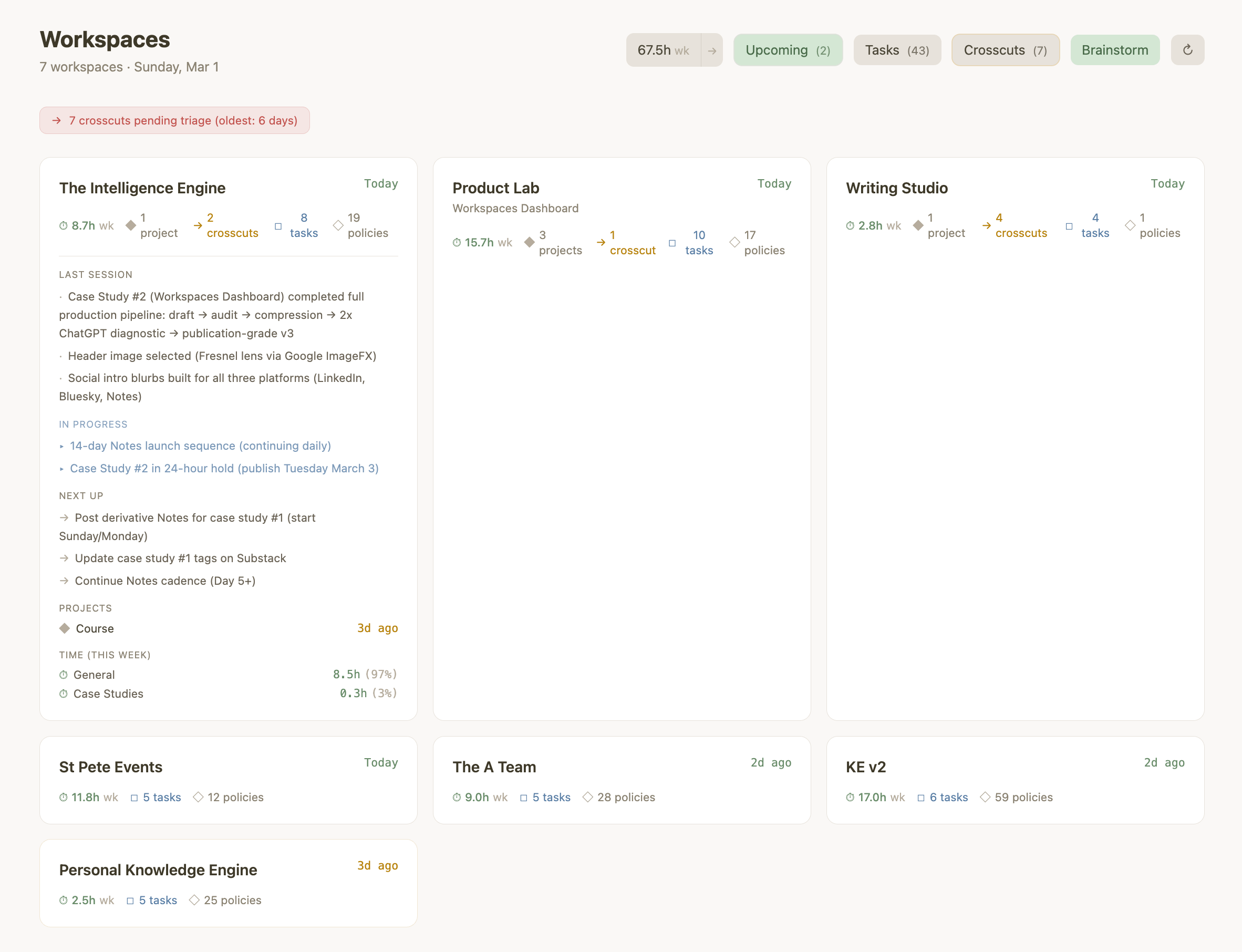
Seven workspaces, each generating decisions, constraints, and cross-workspace handoffs that I couldn’t scan without opening files one at a time. Which workspace had the pending handoff? Which project hadn’t been touched in five days? How much time had I actually spent on Product Lab this week? The intelligence was sitting in markdown files. I just had no surface to read it from.
So I built a dashboard. Three hours, spread across two sessions. Not because the build was simple — because the system running it doesn’t reset.
The Constraint That Shaped Everything
Before writing a line of code, I set one rule: the dashboard is a lens, not a database. It reads from the same markdown files my AI sessions read — status.md, log.md, crosscuts.md, timelog.md — and writes back to them. If the dashboard disappears, nothing is lost. No shadow state. No second source of truth.
That single constraint eliminated an entire category of problems — schema drift, sync conflicts, orphan state — before they existed. And it meant the dashboard could never drift from the system it was monitoring, because they share the same files.
Three Sessions, One Principle
Session one built the parser and card layout — workspace discovery, section extraction, crosscut tracking. Functional, rough, dark-mode. The decisions that mattered were logged: what files to parse, what format to expect, what to show on each card.
Session two started with a design problem. The dark interface felt wrong for a tool I’d use every morning for orientation. I chose a warm neutral palette — cream, sage, white cards. That decision was driven by use, not convention.
Then time tracking. I built a standalone panel — hours per workspace, weekly versus all-time. It worked, but the data sat apart from the workspace cards it was supposed to contextualize. So I moved it inline: hours directly on each card, project-level breakdowns on expand. The principle: place information where the context already lives.
The brainstorm button taught a harder lesson. I’d wired it to open Claude in the browser. But the brainstorm skill needs filesystem access — Cowork mode, not a regular chat. I’d built for the wrong environment because I skipped the constraint check. Even inside a governed system, skipping the constraint check produces wrong work.
Session three replaced thirty-second polling with chokidar — a file watcher pushing updates through server-sent events the instant any markdown file changes. Edit a constraint file in Cowork, and the dashboard reflects it without a refresh. The tool and the system became continuous.
Why None of This Started Over
Every session picked up where the previous one left off. The palette redesign didn’t require re-explaining what the dashboard was — the constraints file already defined it. The time tracking migration from panel to inline didn’t break the parser because session one’s improvements were still there. The chokidar upgrade built on the server architecture from session one.
The Amnesia Tax — the cost of re-explaining context to an AI that forgot everything — was zero across every session. Not because the AI remembered. Because the system did. The constraint file persisted the rules. The status file persisted the state. The decision log persisted the reasoning. Each session inherited everything the previous session knew.
The events app proved a governed system can build fast. The dashboard proved it could modify an existing tool across sessions without breaking earlier architecture. That’s the harder test.
The Honest Part
The 2.65-hour build time is real and tracked. What it doesn’t capture is the months spent building the infrastructure those hours depend on — the constraint files, session protocols, cross-workspace handoff log. That infrastructure is invisible labor, and it’s the only reason those hours were productive.
The dashboard is local-only by design. No login, no hosting, no sync. That’s not a limitation — it’s proof that the core constraint survives at scale. If the dashboard required a server to function, it would fail the same test it was built to pass.
I’ve been using this for days, not months. The compounding loop — visibility makes sessions more productive, productive sessions generate more data for the dashboard — is forming, not proven. I’m watching the pattern, not reporting results from stable state.
What This Is Actually About
Before this system, every tool I built required re-briefing the model about architecture, state, and constraints. The dashboard is the first tool I’ve built where no session required restating context. The difference isn’t speed — it’s that the constraint files, status files, and decision logs did the briefing before I opened a session.
The dashboard took three hours because the system that built it has been compounding for months. The sessions didn’t reset. The decisions didn’t evaporate. The constraints didn’t drift.
Robert Ford builds products, writes stories and essays, and runs six concurrent AI-assisted projects using a governed workspace system. His other writing lives at Brittle Views.